在生成式 AI 模型的生命周期中,推理是继训练之后的第二个阶段:
- 训练:从数据中学习模型权重。
- 推理:把生成式 AI 模型部署到生产环境中并对外提供服务。
过去十年的机器学习热潮,让数十万名数据科学家和机器学习工程师都熟悉了模型从训练到推理的完整生命周期。经典机器学习模型的推理相对简单。在 Baseten 早期,我们曾在轻量级 CPU 上、借助一套简单的软件栈,为使用 XGBoost 等工具构建的模型提供推理服务。
相比之下,生成式 AI 模型的推理要复杂得多。仅仅拿到模型权重,再配上几块 GPU,并不能保证你获得足够快、足够稳定、能够支撑大规模生产的推理服务。要把推理做好,需要三层能力:
- 运行时:把单个模型在单个 GPU 实例上的性能与效率优化到极致。
- 基础设施:在不形成孤岛的前提下,跨集群、跨区域、跨云扩展,并保持高可用性。
- 工具层:为推理工程师提供合适的抽象层级,在控制力与生产效率之间取得平衡。
这三层必须协同工作,才能构建出能够在大规模场景下承载关键任务推理的系统。
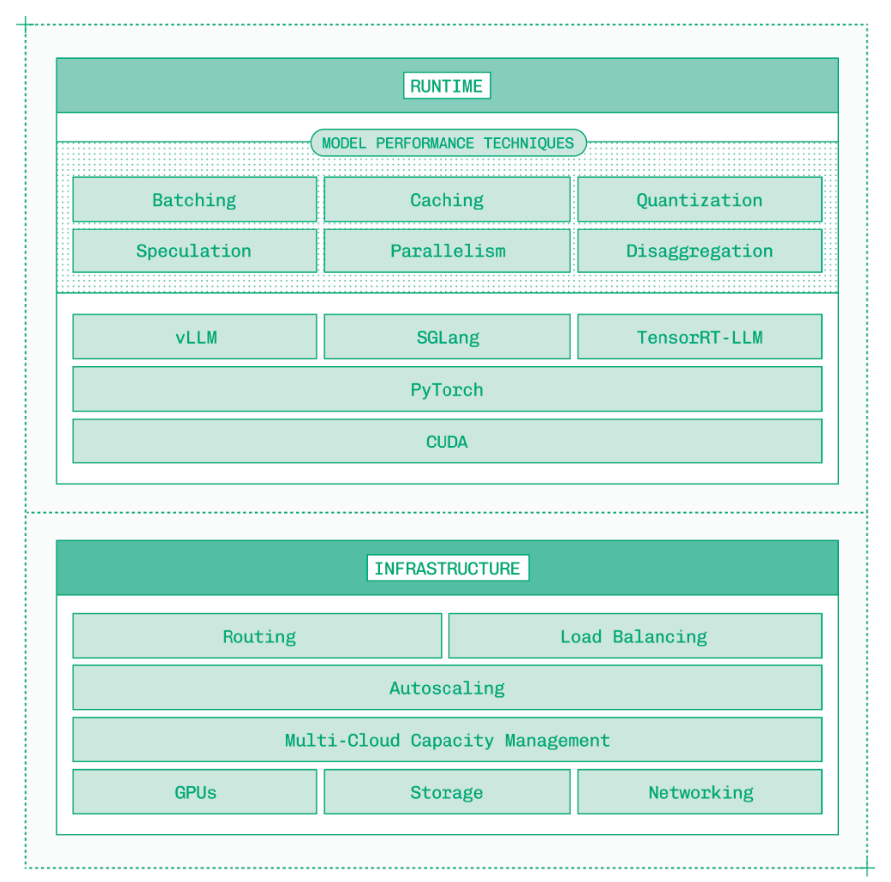
运行时层负责确保模型无论是在单张 GPU 上运行,还是在单个实例内跨多张 GPU 运行,都能尽可能高效、尽可能快。这一层依赖一条复杂的软件栈,从 CUDA、PyTorch,到 vLLM、SGLang 和 TensorRT-LLM 等推理引擎。底层优化至关重要,FlashAttention 这类内核就能带来显著的性能提升。
运行时层还依赖一系列模型性能优化技术,把最新研究成果应用到生成式 AI 推理的具体约束中:
- 批处理:并行处理进入的请求,并在 token 级别交织执行,以提高吞吐量。
- 缓存:对共享前缀的请求复用 KV 缓存,也就是注意力计算的缓存结果。
- 量化:降低模型部分组件的数值精度,以换取更多可用算力并减轻内存压力。
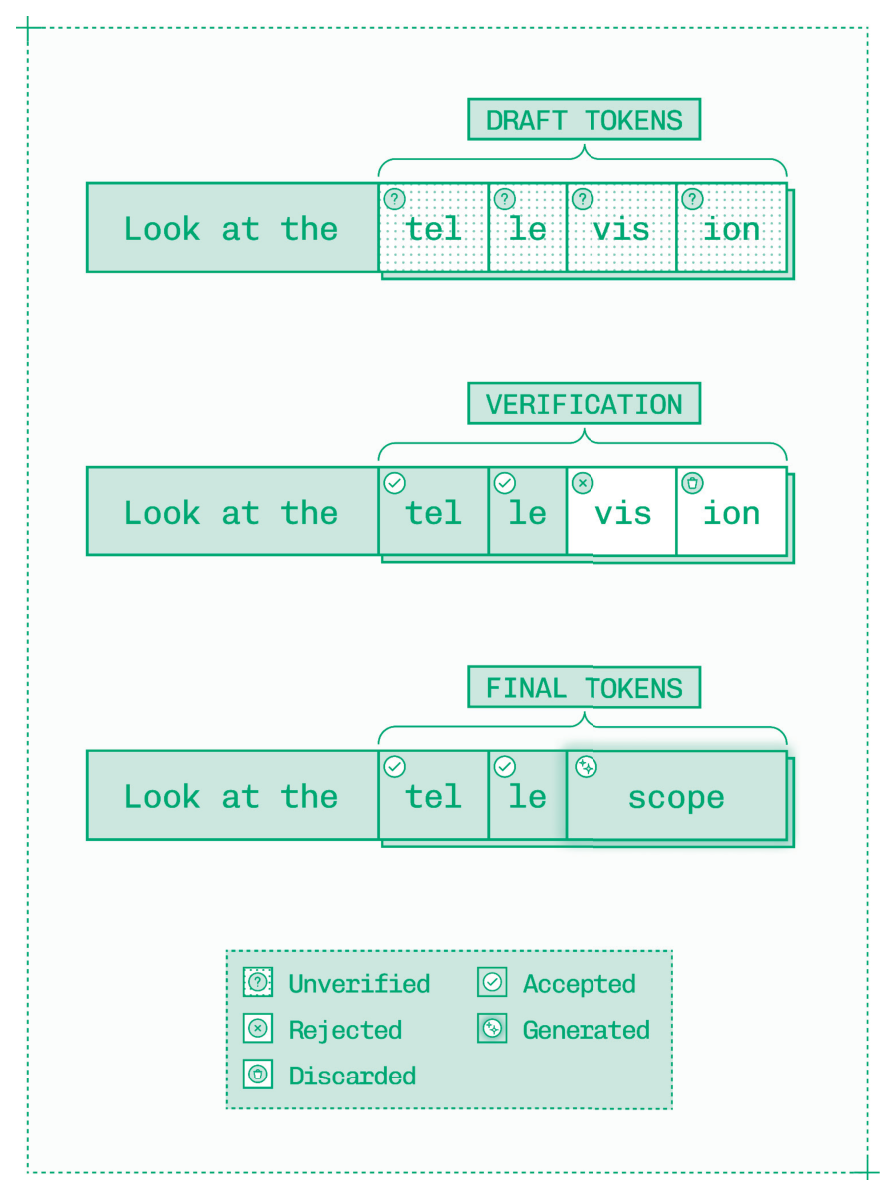
- 推测:先生成并验证草稿 token,在解码阶段一次前向传播中产出多个 token。
- 并行:高效利用多块 GPU 加速大模型,同时避免引入新的瓶颈。
- 解耦:将 LLM 推理的两个阶段,即预填充与解码,拆分到可以独立扩缩容的工作节点上。
这些技术并不只服务于 LLM,也适用于其他模态的模型。视觉语言模型、嵌入模型、自动语音识别、语音合成、图像生成和视频生成等模态,扩展了 AI 系统的能力,也各自带来了不同的推理优化问题。
但运行时优化还不够。无论单个模型服务实例的性能有多强,最终都会遇到超出自身承载能力的流量。这不是 CUDA 的问题,也不是 PyTorch 的问题,而是一个必须在基础设施层解决的系统问题。
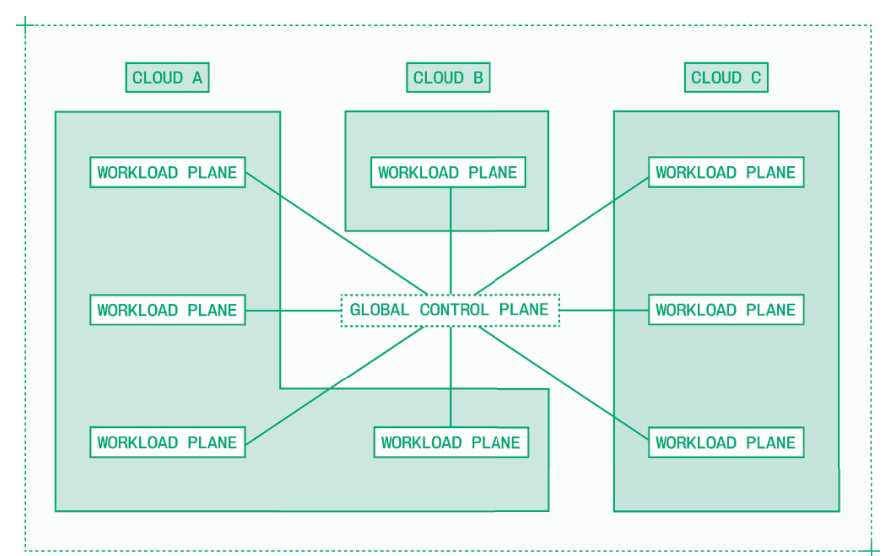
随着规模增长,基础设施问题的性质会发生变化。起初,重点是自动扩缩容:何时增加副本、何时移除副本,以及如何足够快地完成这些动作。再往上走,通常到了数百块 GPU 的规模,问题就会被容量所主导。为了拿到足够多的 GPU,推理工程师会开始把工作负载分散到多个区域和多个云服务提供商上。这很快会形成孤岛:一些集群中的模型可能缺乏资源,而另一些集群却存在闲置容量。基础设施扩展的最终形态,是把所有可用资源都视作一个统一算力池来调度的全球化系统。
经过精心设计的多云基础设施还能提升可靠性,避免单个区域或单个云服务商故障造成整体停机。对于面向全球用户的应用而言,把推理部署到更靠近终端用户的位置,还能降低端到端延迟。
当运行时和基础设施能力建好之后,还需要以恰当的抽象层级把它们交付给使用者。无论是 Baseten 这样的推理服务商,还是内部自建推理平台的团队,都必须思考:作为完整推理平台的第三层,工具层究竟应该提供怎样的开发者体验。
开发者体验没有唯一标准。对于推理来说,一个极端是黑盒:把模型权重交给平台,拿回一个 API;另一个极端,则是只提供计算、网络、磁盘等最基础的构件。更合适的位置通常在两者之间:既让推理工程师拥有足够的控制力,能够有把握地运行关键任务推理;又保留足够的抽象,使他们能够高效工作。
《Inference Engineering》试图为你绘制一张地图,展示支撑推理的运行时、基础设施与工具层中的关键技术与方法。接下来的章节将沿着这三条线索展开:
- 第 1 章“先决条件”:讨论在推理工程真正登场之前就需要完成的产品思考和 AI 工程工作,包括定义用例、制定延迟与成本预算,以及选择并评估要优化和部署的生成式 AI 模型。
- 第 2 章“模型”:介绍 AI 模型的技术架构,从大语言模型到图像与视频生成模型,并说明推理瓶颈位于何处,尤其关注注意力优化。
- 第 3 章“硬件”:从现代 GPU 的规格表讲起,拆解计算与内存,并澄清 NVIDIA 数据中心级产品中的架构与 SKU 区别,最后简要介绍市场上的其他加速器。
- 第 4 章“软件”:从 CUDA 出发建立抽象,一路讲到 PyTorch、Transformers、Diffusers 等框架,以及 vLLM、SGLang、TensorRT-LLM 等推理引擎;同时还会介绍 NVIDIA 最新的大规模分布式模型服务系统 Dynamo。
- 第 5 章“技术”:讨论一系列从前沿研究中演化而来的关键模型性能优化技术,并展示它们如何在生产环境中落地,包括量化、推测解码、KV 缓存复用、模型并行和解耦。
- 第 6 章“模态”:把推理工程从 LLM 扩展到语音和视觉。许多生成式 AI 模型,包括视觉语言模型、嵌入模型、自动语音识别(ASR)模型和语音合成模型,都是在 LLM 架构基础上演化而来,这意味着推理工程师可以使用与 LLM 相同的工具和技术来运行它们。图像和视频生成模型则拥有自己的架构,以及与之对应的性能优化技术。
- 第 7 章“生产部署”:作为全书的收束,梳理如何运维优化后的模型推理服务基础设施,以及如何在其之上构建高性能应用时必须解决的重要问题。
- 第 8 章“推荐阅读”:汇总书籍、论文、文档和博客等延伸资源,供进一步学习。
和 LLM 一样,书也有知识截止日期。本书完稿于 2026 年 1 月。尽管细节会不断变化,但书中的原则、概念和基础技术,仍然能为你在未来多年理解推理工程打下坚实基础。