推理工程依赖于加速器:这是一种专为加载TB级数据并每秒执行数万亿次运算而设计的强大硬件。用于推理的最常见加速器类型是GPU,而推理GPU领域的市场领导者是英伟达(NVIDIA)。本书重点介绍针对数据中心中英伟达GPU的推理工程,但本章第3.4节涵盖了其他数据中心加速器供应商,第3.5节则介绍了本地推理。
纵观各供应商,市场上有三类GPU:
- 数据中心GPU:配备互联高性能GPU的机架式服务器。示例:英伟达B200。
- 工作站GPU:用于专业工作流程的独立桌面GPU。示例:英伟达RTX Pro 6000。
- 个人计算GPU:用于日常使用的独立桌面GPU。示例:英伟达GeForce RTX 5090。
大规模推理使用安装在机架上的数据中心GPU:这些机柜大小如冰箱,配备标准化的电源、网络和冷却系统。英伟达B200等数据中心GPU提供最高的单体性能,但更重要的是,它们包含高带宽的GPU间互联,以高度标准化的配置安装,并在全球数据中心中以数百万计的规模部署。
我怀疑你桌子下面不会有一块B200 GPU。如果有的话,给我发张照片!相反,数据中心GPU上的推理以以下三种模式之一运行:
- 云端:在他人的数据中心中租用GPU,通常是AWS和GCP等超大规模云服务商,或者是Coreweave和Nebius等新兴云服务商。
- 本地部署(On-premise):购买GPU并安装在由您直接控制的数据中心中。
- 气隙隔离(Air-gapped):GPU在本地部署,需要物理访问GPU才能运行推理。
大多数推理工程师使用云端GPU。大型企业和政府采用本地部署和气隙隔离方案,但基于云端的GPU为快速增长的AI产品提供了扩展所需的灵活性和可访问性。
即便如此,驾驭硬件市场依然复杂。从各云服务商之间的差异,到英伟达自身的命名规范,选择合适的加速器存在诸多细微之处。
3.1 GPU架构
GPU是吞吐量导向的计算设备。CPU擅长复杂的串行执行,而GPU则专为简单、大规模并行的工作负载而设计。
具体来说,GPU非常擅长对数千个独立数据块执行同一种统一操作。鉴于AI模型推理本质上是一系列向量和矩阵乘法运算,GPU自然是理想的选择。
虽然高度并行计算的原理很简单,但GPU本身却是极其复杂的技术产品。硬件工程是一个令人着迷的多学科领域,涵盖从芯片供电与散热的物理学,到每个组件制造过程中极为严苛的公差控制。
推理工程师在远高于GPU硬件的抽象层上工作,但对GPU内部运作机制建立清晰的心智模型,对于构建高性能系统至关重要。
3.1.1 计算
如果你熟悉CPU,你可能听说过核心的概念,比如高端游戏电脑中的8核英特尔i9 CPU。
在GPU中,核心有不同的含义。GPU拥有流式多处理器(SM),每个SM包含多个核心。GPU中有三种计算类型:
-
CUDA核心:对单个数字(标量)进行运算。
-
张量核心:对向量和矩阵进行运算。
-
特殊函数单元(SFU):加速某些数学运算,如sin、cos和log。
在衡量GPU的推理计算能力时,应以张量核心的计算能力为基准。SFU对于softmax至关重要,但张量核心负责矩阵乘累加(MMA)指令,这是推理的基础。
MMA中的”累加”步骤是指将两个矩阵的乘积加到基础矩阵上以产生输出,如图3.1所示。

与核心不同,线程的概念在CPU和GPU之间是相似的。CPU拥有数十到数百个线程,而GPU拥有数万到数十万个线程,可以并发工作,在单个时钟周期内切换任务,并并行执行简单指令。
计算能力以FLOPS(每秒浮点运算次数)衡量,数据中心GPU能够达到数万亿或数千万亿FLOPS(分别为teraFLOPS和petaFLOPS)。然而,当你查看规格表时,你会看到张量核心计算能力的两个指标:
-
密集型:如果张量的每个元素都被使用,则为每秒原始浮点运算次数。
-
稀疏型:在具有2:4结构化稀疏性的张量中,50%的值为0,张量核心可以跳过乘以0的运算。
GPU在给定精度下具有稀疏性的FLOPS通常(但并非总是)是相同精度下密集运算的两倍。默认情况下,推理是密集型的,因此请确保查看不含稀疏性的FLOPS。
FLOPS通常随精度每降低一半而翻倍。一块能在16位数字上达到1 petaFLOPS的GPU,将能在8位数字上达到2 petaFLOPS。这与推理密切相关——请务必在相同精度下比较不同GPU的FLOPS。
计算是LLM预填充以及图像和视频生成的瓶颈。如果你在考虑这些使用场景时选择硬件,请选择FLOPS更高的加速器。
3.1.2 内存与缓存
GPU 包含高速板载内存,称为 VRAM。就像”GPU”中的”G”代表图形(Graphics)一样,“VRAM”中的”V”代表视频(Video)——这是对这些加速器最初用途的一种回溯。
如今,VRAM 以 HBM3、HBM3e 或 HBM4 的形式集成到 GPU 中,这些都是高带宽内存的不同代际。GPU 拥有数十乃至数百吉字节(GB)的 VRAM。
任何芯片(无论是 CPU 还是 GPU)上都有两种类型的内存:
-
DRAM(动态随机存取内存):通用型片外内存,容量以吉字节(GB)为单位。
-
SRAM(静态随机存取内存):速度更快、成本更高的片上内存,容量以千字节(KB)或兆字节(MB)为单位。
VRAM 是 DRAM 的一种。GPU 还以缓存的形式在片上集成了 SRAM。GPU 具有三级缓存:
-
L0:单个 Tensor Core 的指令缓存。
-
L1:每个流式多处理器(Streaming Multiprocessor)的共享内存。
-
L2:跨流式多处理器的全局缓存。
H100 GPU 每个流式多处理器拥有 256 KB 的 L1 缓存,片上 L2 缓存总计 50 MB。
VRAM 带宽衡量的是 GPU 核心与 VRAM 之间通过内存总线的峰值传输速率。在实际应用中,这决定了 VRAM 向 GPU 缓存层次结构供给数据的速度。
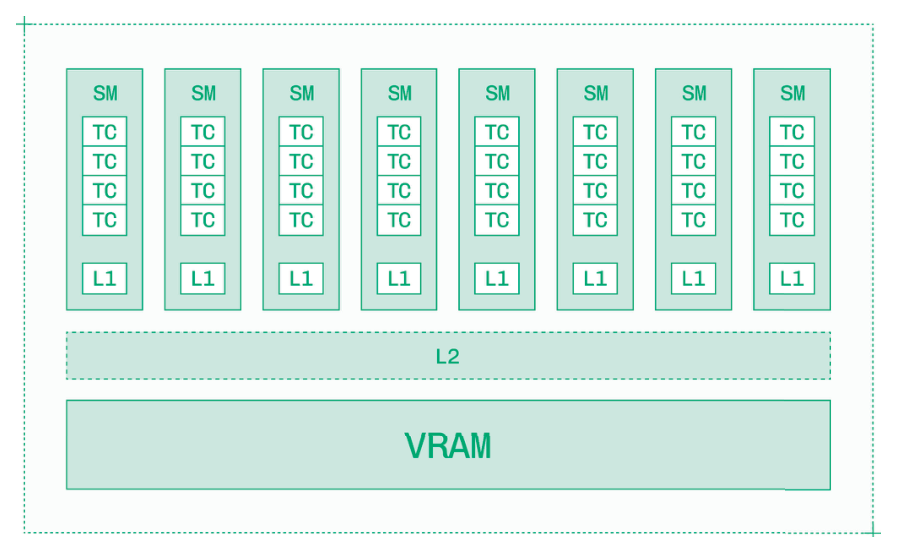
GPU 上 VRAM 的总容量限制了可加载模型的大小。VRAM 需要容纳模型权重,并至少预留 50% 的空间用于 KV 缓存(对于长上下文、大批量推理或视频生成模型,所需空间更多)。
如果可用 VRAM 不足以存放模型权重,加载模型将失败并报 OOM(内存不足)错误。如果预留空间不足,推理将会变慢,甚至因 OOM 而崩溃。
内存带宽是中低批量大小下 LLM 解码阶段的性能瓶颈。高端 GPU 的内存带宽可达每秒数太字节(TB/s)。如果您在选择 GPU 时希望获得更高的每秒生成 token 数,请选择内存带宽更高的加速器,例如用 H200 替代 H100。
3.2 GPU架构世代
硬件迭代周期较慢。从最终确定架构设计到GPU出货,中间需要数年的准备时间。
鉴于AI行业的发展速度,这一流片和测试过程意味着即便是下一代GPU,其设计之时AI模型的能力也与今天截然不同。设计一款在市场上具有持久竞争力的GPU架构,需要对GPU预期使用寿命内用例的演变具有前瞻性。
多年来,训练AI模型一直是GPU的主要用途。如今,随着推理成为主导用例,最新架构正在引入以推理为核心的功能。
GPU的名称,例如B200,由两部分组成:
-
字母:表示芯片所采用的架构世代。
-
数字:标识同一世代中的具体型号。
例如,H100直接取代了上一代的A100,而H200则是同一世代中更大规格的GPU(反过来又被B200所取代)。
编号看起来有些随意,不同世代使用不同的数字组合,但总体规律是数字越大,GPU的规格越大、性能越强、价格越贵。另一方面,架构的字母命名则非常有意义。
NVIDIA每隔一到两年发布一个新的GPU架构,覆盖其从数据中心到个人电脑的所有产品线。每一代架构不仅提升了计算和内存的基础速度,还引入了用于更高效推理的新功能。
自1998年以来,NVIDIA以著名科学家的名字命名其GPU架构。
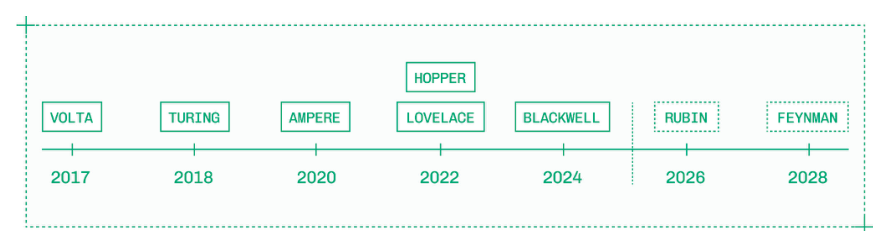
尽管GPU架构的历史可以追溯到数十年前,但推理工程师通常使用最近三到五代的GPU。即使是对成本敏感的工作负载,现代架构的高效性也往往使其在大规模流量场景下更具成本效益,而且更新的架构自然能提供更好的性能。
在低流量或遗留系统中,您可能仍会看到Turing(T4)和Ampere(A10、A100)GPU,但目前大多数部署使用的是Lovelace(L4、L40)、Hopper(H100、H200)或Blackwell(B200、B300)GPU。
Hopper和Blackwell架构提供低精度Tensor Core、高带宽内存以及以推理为核心的功能,而Lovelace GPU则用于小型模型的低成本推理。即将推出的Rubin和Feynman架构分别承诺于2026年和2028年发布,届时将带来更卓越的性能。
3.2.1 Hopper GPU
GPU FP8 算力(密集) 显存 内存带宽H100 1,979 teraFLOPS 80 GB 3.35 TB/sH200 1,979 teraFLOPS 141 GB 4.8 TB/s
Hopper 架构以海军少将葛丽丝·霍珀的名字命名,于 2022 年 3 月随 H100 GPU 首次发布。
Hopper 引入了对 FP8 的支持,FP8 是一种具有 8 位精度的浮点数格式。FP8 张量核心的速度是 FP16 张量核心的两倍,并且传输 FP8 数值所需的内存带宽仅为原来的一半。正如第 5.1 节所讨论的,这并不能线性地转化为双倍性能,但对于可以在 FP8 下运行的工作负载而言,这是一项显著的提升。
Hopper 架构在比前代产品数量更多、速度更快的流式多处理器中加入了第四代张量核心。结合动态规划指令、线程块簇以及分布式共享内存,Hopper GPU 为 CUDA 工程师提供了更多编写高性能内核的工具。
其中一个此类内核是 FlashAttention 3,它提升了 Hopper GPU 上注意力机制的性能和内存效率。FlashAttention 3 充分利用了 Hopper 引入的新异步数据传输和执行特性。
H100 和 H200 GPU 是目前使用最广泛的推理加速器之一,这是有充分理由的。Hopper 架构足够新颖,性能出色,同时又足够成熟,获得了业界的广泛支持和高度优化的内核。H100 和 H200 GPU 的规格恰好适合跨所有模态的常见工作负载。
3.2.2 Ada Lovelace GPU
GPU FP8算力(密集) 显存 内存带宽L4 242 teraFLOPS 24 GB 300 GB/sL40 362 teraFLOPS 48 GB 864 GB/s
Ada Lovelace架构以第一位计算机程序员的名字命名,在Hopper发布仅六个月后首次推出。
这两种架构较为相似,Lovelace更像是Hopper的对应产品,而非继任者。Lovelace同样支持FP8推理。
Hopper专注于AI应用,而Lovelace GPU则更偏向图形领域。Lovelace GPU不支持NVLink互联技术,这是一个重大限制。配备八块Hopper或Blackwell GPU的节点使用这些高带宽互联技术来实现高效的并行计算,而Lovelace GPU只能单独使用,或采用流水线并行等低效的并行方式。
L4 GPU可以作为运行小型模型的经济便捷选择,适用于文本嵌入和计算机视觉等应用场景。
但L40 GPU通常并不是推理的理想选择。在相同显存占用的情况下,多实例GPU(第3.3.2节)在部分H100上能提供更高的算力和内存带宽。
3.2.3 Blackwell GPU
GPU FP8算力(密集) 显存容量 显存带宽B200 约5 petaFLOPS 192 GB 最高8 TB/sB300 约5 petaFLOPS 288 GB 最高8 TB/s
Blackwell架构以数学家David Blackwell命名,于2024年11月随B200 GPU首次发布,随后推出了B300。虽然B100也存在,但它并不常用于推理场景。
Hopper引入了FP8,而Blackwell在低精度计算方面更进一步,支持FP4(一种4位浮点格式),以及一系列微缩放格式(MXFP8、MXFP4、NVFP4),以在推理过程中更好地保留精度质量。第5.1节将详细介绍这些格式。
Blackwell在Hopper异步编程范式的基础上进行了扩展,新增了更多用于张量内存与全局内存之间数据加载和存储的功能。更新后的FlashAttention 4内核大量依赖在异步流水线中进行分块加载、计算和写入。
B200和B300是推理领域新的黄金标准,为大型语言模型和视频生成等高要求工作负载提供了最高性能。Blackwell GPU的软件支持、优化内核及正式商用供货均已在近几个月内陆续落地,标志着推理行业正经历一次重要的转型。
3.2.4 Rubin GPU
Rubin架构以天文学家薇拉·鲁宾的名字命名,将于2026年作为NVIDIA的下一代GPU架构正式发布。
在评估新架构时,重要的是在能够运行实际性能基准测试之前保持审慎判断。新架构的推出,加上整个行业软件支持的跟进,通常需要大约一年时间才能完全普及。
在本文发布时,关于Rubin已有一些具体细节。Rubin架构采用HBM4,这是对HBM3和HBM3e的升级,而HBM3和HBM3e此前已为最近几代GPU提供支持。受内存带宽限制的推理任务(如LLM解码)将从这种更高吞吐量的显存中受益。
Rubin还引入了全新的CPX,这是一块专为计算密集型任务(如LLM预填充)而设计的独立芯片。CPX将成为NVIDIA面向大规模推理的机架级系统的一部分。
在Rubin之后,NVIDIA将于2028年发布Feynman。目前关于Feynman的细节知之甚少,但它很可能支持更大、更强大的芯片,并配备更快的内存架构。
3.2.5 Grace 和 Vera CPU
NVIDIA 还提供自研的基于 ARM 架构的 CPU,这些 CPU 与 GPU 集成在 GH200 和 GB200 等超级芯片上。“G”代表”Grace”,即 Grace Hopper(与 Hopper GPU 相对应)。
NVIDIA Grace CPU 整体计算性能强劲,但对于推理而言,更重要的是它在 CPU 与 GPU 之间提供了更高带宽的连接。Grace CPU 采用 NVIDIA NVLink 芯片间互联技术,实现 CPU 与 GPU 内存之间高达 900 GB/s 的双向带宽。
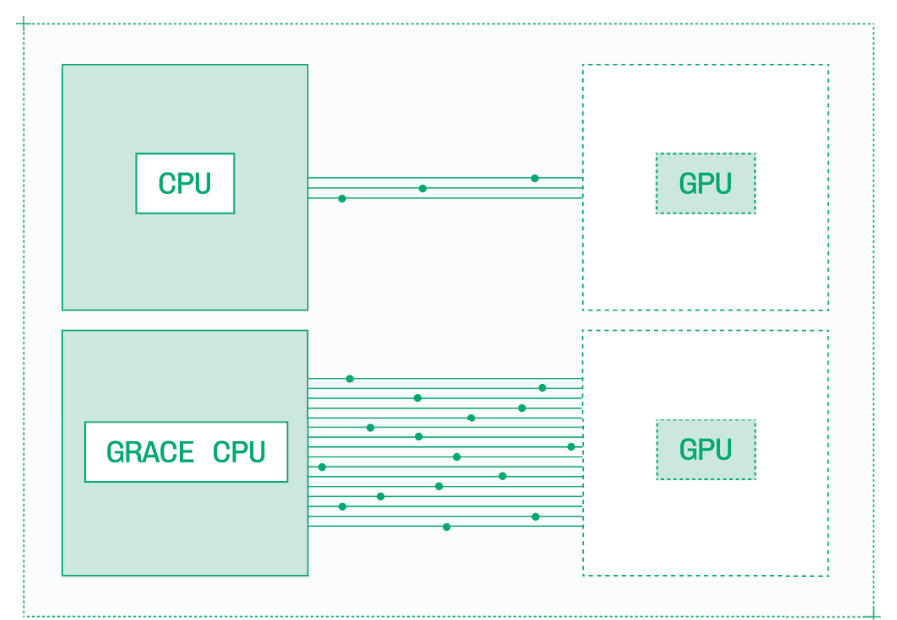
这种 CPU 到 GPU 的互联速度比 PCIe 或其他 CPU 与 GPU 之间的标准连接快数倍。
某些推理场景需要将重要信息(如 LoRA 微调权重和前序推理调用的 KV 缓存)卸载到 CPU 内存中,因为 CPU 内存远大于 GPU 内存。使用 Grace CPU 时,这些信息的读取速度可以大幅提升。
对于 Rubin 架构,Vera CPU(以 Vera Rubin 命名)取代了此前用于 Hopper 和 Blackwell 系统的 Grace CPU。
3.3 实例
云端 GPU 分配的最小单元是实例。实例是一种虚拟机,包含以下组件:
-
GPU(设备):用于推理任务的一个或多个 GPU。
-
CPU(主机):用于处理不在 GPU 上运行的任何任务的通用计算单元。
-
内存(主机内存):用于 CPU 操作的通用内存(即传统意义上的 RAM)。
-
存储:用于加载和存储大型文件的磁盘内存。
-
网络:连接到数据中心乃至公共互联网的物理网络连接。
-
互联:用于同时在多个 GPU 上运行的物理 GPU 间及节点间连接。
并非所有 GPU,也并非所有实例都是一样的。根据云服务提供商的不同,实例在计算能力、内存、存储和互联方面各有差异。尽管 NVIDIA 提供了自己的参考架构,但每家云服务提供商最终都会按照自己的偏好来构建系统。
即便是 GPU 本身,也可能因实例不同而有所差异。例如,NVIDIA A100 GPU 有两种形态:PCIe 和 SXM。但大多数在 A100 上运行的推理任务使用的是 SXM GPU,因为其内存带宽比 PCIe 版本高出百分之五。
在配置实例时,准确了解所获得的配置至关重要。实例的任何组件,不仅仅是 GPU,都可能在推理过程中成为性能瓶颈或故障点。
3.3.1 多GPU实例
通常,一个模型太大而无法在单个GPU上运行,或者推理工程师希望同时使用多个GPU来提升性能。运行像DeepSeek这样的大型模型或视频生成这类高需求模态,往往需要两个、四个、八个甚至更多GPU。
GPU的标准单元是节点,每个节点包含八个独立的GPU。例如,一个B200节点包含八个B200 GPU。
这些GPU通过两种系统相互连接:
-
NVLink:GPU之间的点对点通信层,在Blackwell上带宽高达1800 GB/s,在Hopper上高达900 GB/s。
-
NVSwitch:基于NVLink之上的全互联通信层,用于协调节点内所有GPU之间的通信。
这些高带宽互联使得将单个模型的推理任务分散到多个GPU成为可能,最多可扩展至完整的8-GPU节点。
但有时一个节点还不够。在超过八个GPU上运行极高需求的推理工作负载,需要节点之间具备高带宽互联。
NVIDIA GPU节点间互联的标准是InfiniBand。InfiniBand与以太网等网络技术竞争,2019年NVIDIA收购了生产InfiniBand的Mellanox公司。
InfiniBand比NVLink慢得多,每个网络接口控制器(NIC)的规格最高为400 Gb/s。但它是市场上最快的节点间互联方案——以太网每个NIC最高仅为100 Gb/s。
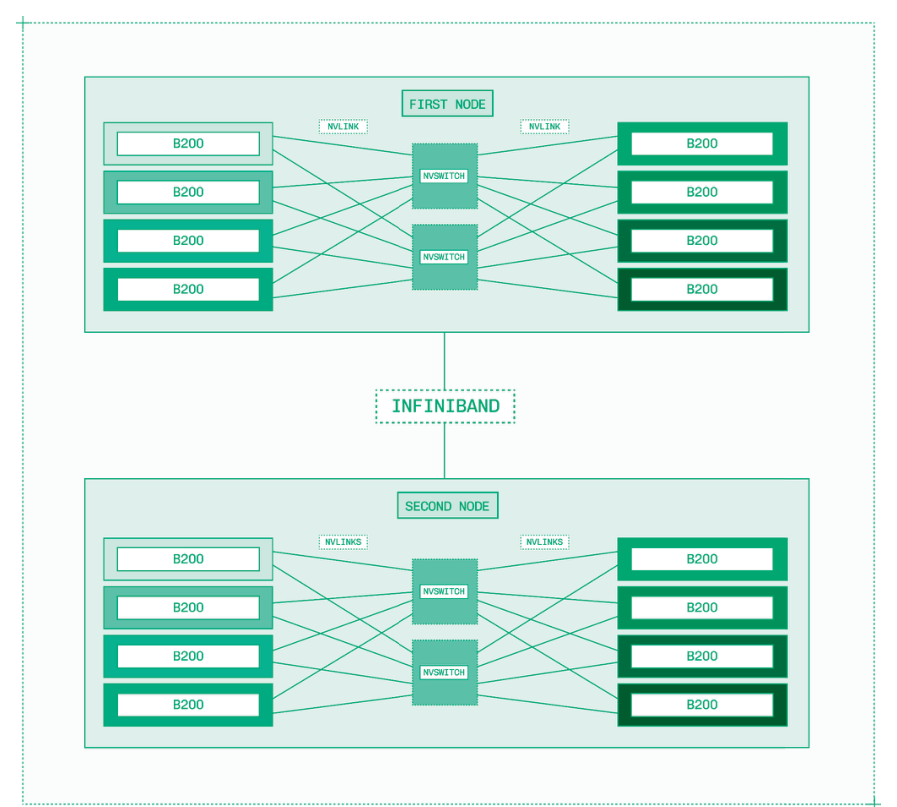
并非每个云服务提供商都使用InfiniBand。一些提供商提供自己的互联方案,而另一些则仅在部分GPU上配备InfiniBand。在配置GPU时,请务必确认所提供的互联类型及其带宽。
除InfiniBand外,NVIDIA还为超过八个GPU的NVLink连接提供高端解决方案。其NVL72 GB200系统在整机柜系统中集成了72个Blackwell GPU和36个Grace CPU。这些系统为承载全球最大模型的高强度流量提供了强大的吞吐量。
NVIDIA Vera Rubin NVL 144 CPX是这一大型系统的下一代产品,配备了更新的Vera CPU、Rubin GPU以及全新的Rubin CPX。
在使用多GPU和多节点系统时,需牢记各互联的相对带宽。当NVLink等互联的速度比InfiniBand快一个数量级时,它在成为瓶颈之前可以处理多得多的数据。第5.4节和第5.5节中讨论的并行化与解耦技术,正是通过合理利用这一拓扑结构,来实现跨多个GPU的高性能推理。
3.3.2 多实例 GPU
有时,推理工程师会遇到相反的问题:GPU 对于模型来说太大了。
使用 Hopper 和 Blackwell 等较新的高性能架构需要 H100 或 B200 等 GPU,这些 GPU 具有相对较大的计算和内存配置。对于参数量在几十亿或更少的模型,很难有效利用这些 GPU。即使使用较大的批处理大小,宝贵的 GPU 资源也会被浪费。
与其在较旧、性能较低的 GPU 上运行小模型,不如将这些轻量级工作负载运行在较新高性能 GPU 的部分资源上。
多实例 GPU(MIG)是较大 GPU(包括 A100、H100、H200 和 B200)中的一种硬件级功能。这些 GPU 最多可以被分割成七个部分。这些分片 GPU 还会获得 CPU、RAM、存储和其他资源的切片,以组成一个实例。
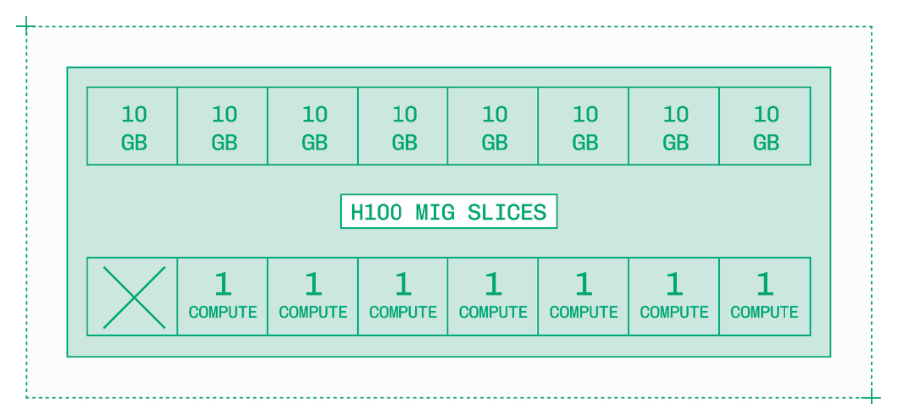
例如,具有三个切片的 H100 MIG 拥有约 3/7 的可用计算资源,并可访问最多一半的总 VRAM,即 40 GB。它还包含分配给底层 H100 的约一半 CPU 核心、CPU 内存、存储和网络带宽,以组成一个实例。
软件工程通常以 2 的倍数为单位,因此七个计算切片可能看起来有些奇怪。计算切片由 GPU 中的流式多处理器(SM)组成。GPU 通常没有整洁的 2 的倍数 SM 数量,例如,SXM H100 GPU 有 132 个 SM。因此,创建了七个均等大小的计算切片,剩余的 SM 则处于空闲状态。
对于 Orpheus TTS 这样的小模型(一个 3B 参数模型),使用两个 MIG 实例有时比将整个 GPU 分配给单个实例更能有效利用资源。
3.4 其他数据中心加速器选项
NVIDIA 在 AI 硬件市场的领先地位使其成为全球市值最高的公司。但它远不是唯一一家能够运行 AI 推理的硬件制造商。
从亚马逊、谷歌等行业巨头,到大量初创企业,竞争对手们正在投入数十亿美元开发和制造 NVIDIA GPU 的替代产品。
虽然本书重点介绍如何在 NVIDIA GPU 上优化推理,但以下是其他可用于运行模型推理的主要硬件选项的简短列表。
| 公司 | 阶段 | 旗舰产品 |
|---|---|---|
| AMD | 上市公司 | MI350 GPU:一款在 AMD 自有软件栈上具有竞争力规格的数据中心 GPU。 |
| AWS | 上市公司 | Inferentia 和 Trainium:一对专为 AWS 上的推理和训练分别定制的芯片。 |
| Cerebras | 初创企业 | WSE-3:一款具有极高内存带宽的晶圆级芯片,可消除解码瓶颈。 |
| Etched | 初创企业 | Sohu:一款专为 Transformer 架构设计的专用集成电路(ASIC)。 |
| Furiosa | 初创企业 | RNGD:一款专为张量收缩运算设计的高能效加速器。 |
| 上市公司 | TPU:张量处理单元,是专为推理和训练构建的 AI 专用 ASIC。 | |
| Groq | 初创企业 | LPU:一种可组合的语言处理单元,依赖 SRAM 实现高内存带宽。 |
| Qualcomm | 上市公司 | Cloud AI 100 Ultra:一款由多个高能效移动 GPU 组成的全尺寸 GPU。 |
| Sambanova | 初创企业 | RDU:一种可重配置数据流单元,为万亿参数模型提供大容量内存分配。 |
GPU 是相当通用的加速器。每家与 NVIDIA 竞争推理工作负载的硬件公司,都在押注自身产品能够胜出的某一特定优势:
-
内存带宽:Cerebras 和 Groq 等初创企业通过在超高带宽内存上加速解码,为大语言模型实现高每秒 token 数。
-
能效:Furiosa 和 Qualcomm 等公司设计低功耗芯片,从而降低运营成本。
-
平台集成:亚马逊和谷歌等企业与其云服务平台及专有闭源模型进行深度集成。
尽管这些加速器选项各有其擅长的应用场景,但它们也面临着共同的挑战:
-
软件:没有 CUDA,硬件提供商必须为其加速器从头重建整个推理软件栈。
-
制造:企业需要组装人类有史以来创造的最复杂的物体。
-
分发:芯片制造完成后,提供商需要将其安装上线,才能将算力投放市场。
竞争加速创新。数据中心拥有更多硬件选择的市场,对每一位推理工程师都是有利的。随着推理工作负载变得越来越有价值,这一领域的竞争只会愈发激烈,数据中心以外的选项探索也将不断深入,例如本地推理。
3.5 本地推理
本地推理,也称为边缘推理、客户端推理或设备端推理,是指直接在终端用户的设备上运行AI模型推理,而非在集中式服务器上运行。
与服务器端推理相比,客户端推理具有四大显著优势:
-
零网络延迟:无需通信开销,可节省数十甚至数百毫秒。
-
独立性:不依赖网络连接,也不受服务器高流量或宕机的影响。
-
隐私保护增强:终端用户的数据永远不会离开其设备。
-
成本:数据中心GPU价格昂贵,而边缘推理对开发者而言是免费的,从而开启了全新的商业模式。
本地推理理论上听起来完美无缺,但在实践中,大多数推理仍在云端进行是有原因的。本地推理存在四大弱点,限制了其应用范围:
-
硬件能力:即便是高端消费级桌面设备,其速度和算力也仅是数据中心GPU的一小部分。
-
散热限制:本地设备的散热能力不如数据中心,进一步限制了其速度和功耗表现。
-
碎片化支持矩阵:硬件与软件的无数种组合使标准化面临挑战。
-
电池续航:推理是一项高负载任务,会迅速耗尽笔记本电脑和智能手机的电池。
在使用本地推理进行开发时,牢记目标受众至关重要。AI爱好者可能拥有最新最强的手机和高性能电脑,但普通用户更有可能使用配置较低的旧设备。
本地推理正从实验阶段迈向生产阶段,在硬件和软件领域拥有强大的生态系统,并与开放模型世界紧密相连,社区活跃而充满活力。
3.5.1 桌面推理
经典的本地设备是配备一两块NVIDIA或AMD高端消费级GPU的工作站或游戏PC。虽然研究人员和爱好者确实使用这类配置,但它们只占桌面推理市场的一小部分。
苹果正日益成为桌面推理市场的领导者。苹果定制的M系列CPU和GPU共享统一内存,使GPU推理能够访问更大的内存容量,尽管速度相对较慢。
目前市场上苹果和NVIDIA提供的最高端选项,清晰地展示了内存容量与速度之间的权衡。
| 硬件 | NVIDIA RTX 5090 | Apple M3 Ultra |
|---|---|---|
| 内存 | 32 GB | 512 GB |
| 带宽 | 1,792 GB/s | 819 GB/s |
| 成本(整机) | $5,000 | $10,000 |
这一趋势在价格更合理的中端硬件中同样延续。低端计算机(如Chromebook)则不具备运行任何有实际意义的本地推理的能力。
由爱好者主导的开源生态系统专注于在台式机和笔记本电脑上运行前沿开源模型。如今,借助Ollama和llama.cpp等工具,在高端个人硬件上运行经过激进量化的1000亿参数以上的模型已成为可能。
混合专家模型(Mixture of Experts)的日益普及也为桌面推理带来了利好。这些模型具有更少的活跃参数,这意味着单个用户的单次请求只会涉及模型全部权重的一小部分。
图像生成在个人电脑上也相当流行,尤其是通过ComfyUI——一种将多个图像模型组件组合成单一流水线的工具。
较小的语言模型以及语音等其他模态也可以在中端计算机上运行,行业正在快速开发WebLLM等浏览器推理库及其他跨平台标准,以将这些能力从早期采用者推广至主流用户。
3.5.2 移动端推理
目前,在移动设备上进行本地推理是设备端工作负载的主要形式。两大主流操作系统均为开发者提供了将边缘推理集成到应用程序中的工具:
-
Android:谷歌的 AI Edge SDK 和 ML Kit GenAI API 可与 Gemini Nano 及开源 Gemma 模型进行交互。
-
iOS:苹果的 Foundation Models 和 Core ML 框架为跨模态模型提供了相应的 API。
移动设备的硬件能力和电池容量极为有限,这使得推理工作更具挑战性。即便是高端手机,也难以运行参数量超过十亿至二十亿的模型。
尽管如此,某些模态仍非常适合在手机上进行边缘推理。例如,转录和语音合成模型对延迟较为敏感,而部分模型体积足够小,可以在现代手机上实现实时运行。其他独立任务(如翻译)也可通过小型微调模型在边缘设备上完成处理。
与其他软件一样,推理的未来并非局限于本地或云端,而是两者协同配合,共同提供快速、流畅的用户体验。小型模型和简单查询将在终端用户设备上运行,而更高要求的工作负载则仍将依托云端数据中心的 GPU 来完成。